
Durch Befragungszeitreihen zu besserer Datenqualität
Seit jeher werden neue Erkenntnisse durch Befragungen erschlossen, um den Puls der Zeit erfassen und verstehen zu können. Doch stellt man immer wieder in der Branche fest, dass auch tiefgreifende Fehlentscheidungen getroffen werden können. Und das geschieht trotz der Datenlage, die anhand ihrer großen Fallzahl erstmal vielversprechend wirken mag. Bleibt die Datenqualität allerdings ungeprüft, so werden womöglich profitable Kundensegmente nicht erkannt und Produkte auf den Markt geworfen, die noch seltener Absatz finden als das Blei im Regal daneben.
Mitverantwortlich für mangelhafte Ergebnisse sind hierbei Umfrageteilnehmer, die mit realitätsfernen Angaben die Ergebnisse der ehrlichen Masse verzerren, was insbesondere in Online-Studien eine Herausforderung darstellt. Uns Forscher beschäftigt immer wieder aufs Neue die Frage: Wie können wir hier die sprichwörtliche Spreu vom Weizen trennen?
Schaffen es doch mal Befragte mit fragwürdigen Absichten durchs Screening ohne geflaggt (= für weitere Prüfungen zur Sicherung der Datenqualität markiert und hinterher unter Umständen entfernt) zu werden, so haben wir immer noch ein paar Asse im Ärmel. Neben inhaltlichen Plausibilitätsprüfungen findet sich ein Bereinigungsansatz bei der Begutachtung der Befragungszeitdaten. Schließlich bietet es eine weitere Dimension zur Prüfung von auffälligen Befragten, die sich sehr gut mit der Inhaltskontrolle ergänzt und genau drauf werfen wir heute einen tieferen Blick.
Ein erster Überblick
Im Regelfalle bietet das Survey-Tool Ihres Vertrauens standardmäßig eine Variable an, die Ihnen aufzeigt, wie viel Zeit ein Befragter insgesamt in der Befragung verbracht hat. Optimalerweise haben Sie bereits zu Feldbeginn Ihren Fragebogen auch ausgiebig auf den Zeitaufwand getestet und sollten abschätzen können, welche Zeit ein Mensch unmöglich unterschritten haben könnte, wenn die Fragen wirklich gelesen werden. Dies lässt sich als Daumenregel für eine Untergrenze nutzen, anhand derer schon mal anomales Verhalten – hier Speeder – ermittelt werden kann.
Folgendes Beispiel: Nehmen wir an, wir haben eine simple Online-Studie ohne Filterführung durchgeführt. Die Netto-Stichprobe umfasst dabei 652 Fälle. Die Betrachtung der Befragungsdauer pro Befragten zeigt uns folgende Parameter:
| Parameter | Minuten (dezimal) | Minuten umgerechnet |
| Mittelwert | 14,91 | 14 Minuten 54 Sekunden |
| Median | 13,11 | 13 Minuten 6 Sekunden |
| Standardabweichung | 7,57 | 7 Minuten 34 Sekunden |
| Minimum | 3,94 | 3 Minuten 56 Sekunden |
| Maximum | 63,83 | 63 Minuten 50 Sekunden |
Um ein besseres Gefühl für die Verteilung zu bekommen, werfen wir noch einen Blick auf das Histogramm über die Befragungsdauer:
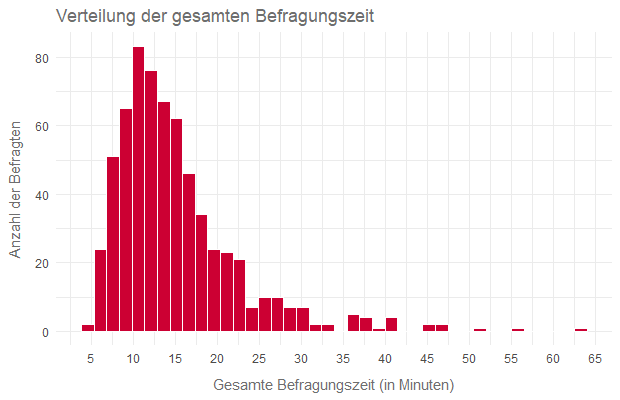
Der reguläre Befragte scheint sich nach den Daten ca. 13 – 15 Minuten mit dem Fragebogen zu beschäftigen. Die Ausreißer nach oben sind recht typisch für Teilnehmer, die mal entweder sehr lange zum Nachdenken benötigen oder einfach an einer oder mehreren Stellen den Fragebogen unterbrechen und sind damit zumindest logisch erklärbar. Jedoch sollten diese nicht aus den Augen gelassen werden (darauf kommen wir nochmal zurück).
Konkreter setzen wir erstmal bei der Untergrenze an, und zwar wissen wir aus dem Fragebogentest vor Beginn der Feldzeit, dass der Bogen nicht unter fünf Minuten beantwortet werden kann, wenn man selbst Schnellleser berücksichtigt. Zweifelsohne gibt es hier jedoch ein paar, die in diese Kategorie fallen und entsprechend bereinigt werden können. Übrig bleiben nach diesem Schritt schon mal 644 Fälle.
Dieser Bereinigungsansatz ist noch relativ eingängig und findet in der Praxis auch häufige Anwendung. So manche legen bereits an dieser Stelle den Hammer nieder, doch insgeheim wissen wir, dass wir gerade nur an der Oberfläche gekratzt haben. Speeder über die Gesamtdauer zu identifizieren ist eine Sache, doch was ist zum Beispiel mit den Befragten, deren gesamte Befragungszeit unauffällig ist, aber bei einer einzigen Frage eine exorbitant hohe Dauer aufweisen, abgesehen von dieser einen Frage aber lediglich zwei (!) Minuten ihrer Zeit investiert haben? Auch die sollte man gezielter betrachten.
Dies gelingt dadurch, indem man sich pro Frage die Betrachtungsdauer als Variable ausgeben lässt. Die Nutzer unserer Befragungslösung GESS Q. haben es dabei besonders leicht; die können es sich mit einer Befehlszeile bequem komplett ausgeben lassen, und zwar mit:
writeViewingTime = all;
Dieser Befehl erzeugt uns sogenannte Duration-Variablen, womit wir uns einen Überblick über die Ansichtszeiten pro Frage als Zeitreihe bei den übrigen 644 Fällen verschaffen können – hier gemessen am weniger ausreißerempfindlichen Median:
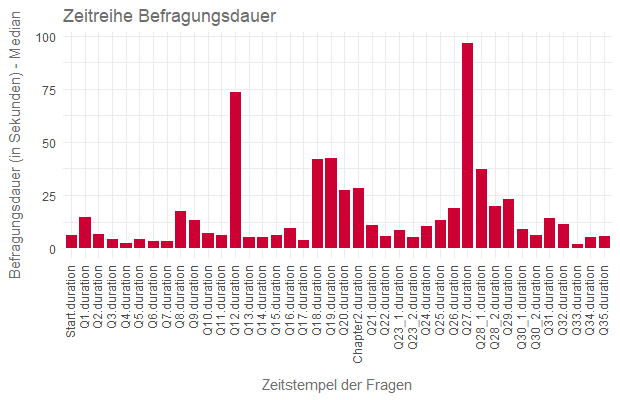
Besonders die Fragen Q12 und Q27 fallen mit hohen Werten auf, was erstmal nicht verwunderlich ist, da es sich bei beiden Fragen um größere Matrixfragen mit über zehn Items und einer fünf-stufigen Skala handelt. Möchte bedeuten: Die erfordern auch einen gewissen Zeitaufwand. Genau dies sind aber auch die besten Gelegenheiten für diejenigen, die besonders viel Zeit sparen wollen, da sie mehr damit beschäftigt sind zu klicken als zu verstehen.
Nachdem wir uns einen Überblick verschafft haben, können wir nun etwas tiefer in die Materie einsteigen. Dabei werden wir an dieser Stelle nun zwischen grundsätzlich zwei Befragungsszenarien unterscheiden, auf die wir im weiteren Detail eingehen.
Szenario 1: Speeder
Die Speeder, von denen wir hier nun sprechen, haben bereits unseren Test auf Totaldauer überlebt. Nun haben wir allerdings auch die Informationen über die einzelnen Fragen und können somit sehr viel gezielter agieren. Beispielsweise können wir auch hier auf das Prinzip zurückgreifen, mit dem wir bereits die fünf Minuten als KO-Kriterium für die gesamte Befragungsdauer festgelegt haben – und zwar mittels Tests auf realistische Mindestdauer. Gerade bei zeitaufwendigen Fragen (hier die Q12 und Q27) können wir recht einfach ermitteln, welche Zeit benötigt wird, um Fragetexte und Antworten überhaupt gelesen haben zu können. Wird diese Schranke zu oft von einem Befragten unterschritten, können wir diesen flaggen.
Um ganz sicherzugehen, könnten wir nun von ausgewählten Fragen die untersten Perzentile der Zeitangaben (sprich die mit den niedrigsten Befragungszeiten) zusätzlich betrachten. Abhängig vom Vertrauen gegenüber der Datenquelle kann schon ein Perzentil von 3–4% ausreichen, um potenziell fragwürdige Datensätze zu markieren, da man auf diese Weise die wirklich schnellen Befragten abschöpft. Wendet man diesen Ansatz in unserer Beispielstudie auf die Fragen Q12 und Q27 an, so ergeben sich bei einem 4%-Perzentil die Grenzen von ~37 Sekunden bei Q12 und ca. ~29Sekunden bei Q27, die als Grenzwerte für unsere Markierung dienen.
Szenario 2: Dragger
Einen vergleichbaren Ansatz können wir uns auch bei den besonders langsamen Befragten zu Nutze machen. Nutzen wir hier bspw. das 98%-Perzentil bei den bekannten Fragen Q12 und Q27, so erhalten wir Grenzwerte in Höhe von ~256 Sekunden (Q12) und ~354 Sekunden (Q27), durch die wir Befragte mit besonders langen Zeiten zur weiteren Prüfung markieren können.
Der schlichte Cutoff anhand von Perzentil-Grenzen einzelner Duration-Variablen ist hierbei nur eine von mehreren Möglichkeiten auf verdächtige Fälle zu stoßen. Zur Erkennung von Anomalien können wir ergänzend auf Klassifizierungsmethoden wie dem Clustering zurückgreifen. Abhängig von der Datenlage und den mitgegebenen Parametern erhalten wir auch auf diesem Wege nützliche Vorschläge zur weiteren Prüfung.
Ohne Sie groß mit zu technischen Details zu irritieren, hier ein Beispiel: Ein geeignetes Verfahren ist der Clusteralgorithmus DBSCAN (kurz für „Density-Based Spatial Clustering of Applications with Noise“), der anders als das klassische K‑Means- oder K‑Median-Clustering imstande ist, Datensätze als Rauschen bzw. Ausreißer einzuordnen, wenn es sich nicht in der Lage sieht, sie einem Segment zuzuordnen. Hier sind dies Befragte, deren Verlauf über die Befragungszeiten von anderen zu stark abweicht. Nachdem Sie Ihre Duration-Variablen sauber standardisiert haben, versucht der Algorithmus gemäß dem k‑Nearest-Neighbor-Ansatz (= „Finde den nächsten Nachbar zu mir“) die nächstgelegenen und damit ähnlichsten Befragten zu identifizieren. Liegen bestimmte Daten zu weit auseinander, so werden solche als „Ausreißer“ eingestuft.
Angewandt auf unseren Beispielfall können wir dies über das folgende Streudiagramm visualisieren.
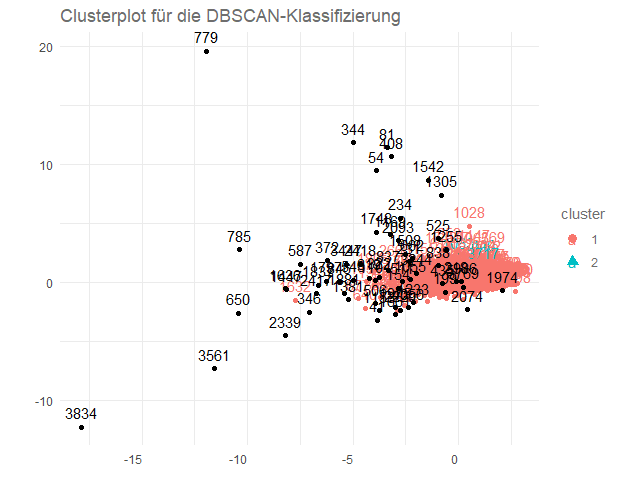
Hinweis zur Grafik: Bitte beachten Sie dabei, dass die beiden Achsen sich aus den ersten beiden Komponenten einer Principal Component Analysis (kurz „PCA“) auf Basis der Duration-Variablen ergeben haben, um den Sachverhalt geeignet darzustellen.
Ein kurzer Blick auf die Grafik zeigt uns zwei Cluster und eine Menge von schwarzen Punkten, die hier die Ausreißer darstellen. Da das Cluster 2 auch nur sehr schwach besetzt ist, ordnen wir diese Fälle den Ausreißern zu. Die Beschriftung entspricht hierbei der Fallnummer aus der Erhebung. Mit Hilfe dieser Methode können wir eine zusätzliche Validierungsschicht in unsere Datenbereinigung einfügen.
Der Vorteil dieses Ansatzes liegt darin, dass man über die reine Grenzwertbetrachtung hinaus auch häufiger Fälle aufspüren kann, die im Rahmen der Zeitreihenbetrachtung ein schlichtweg „ungewöhnliches Verhalten“ an den sprichwörtlichen Tag legen. Solche Teilnehmer benötigen tendenziell länger bei eigentlich kurzen Fragen und umgekehrt. Dies setzt voraus, dass man zumindest die wirklichen Extremwerte schon vorher behandelt und herausselektiert hat, denn je größer die Abstände einiger weniger, desto eher werden ungewöhnliche Fälle als „normal“ erfasst. Dies ist auch mitunter ein Grund, weswegen sich das Verfahren zur Identifizierung von Speedern nur bedingt eignet.
An dieser Stelle haben wir nun mehrere Möglichkeiten, um weiter zu verfahren. Nach Anwendung der vorherigen Methoden haben wir anhand der Zeitverlaufsdaten von den 644 Ausgangsfällen bereits 86 Fälle als „ungewöhnlich“ klassifiziert. Beispielsweise könnte man bei denjenigen, die wegen besonders großer Zeitwerte bei einer oder mehreren Fragen aufgefallen sind, die Sekundenanzahl der Frage mit dem größten Wert von der Totalzeit des Befragten abziehen und schauen, wie viel von der Totalzeit noch übrigbleibt.
In der Praxis bedeutet dies bei einem willkürlich gewählten Beispiel: Befragter Nr. 785 hat bei der Frage Q19 etwas über eine Minute benötigt, während der Median bei der Frage gerade mal bei ~38 Sekunden liegt. Dieser Befragte hat eine Gesamtbefragungszeit von 6 Minuten und 12 Sekunden und damit wäre er, wenn er dem Median bei Q19 entsprechen würde, abzüglich dieser einen Frage immer noch bei über fünf Minuten. Damit läge er über der KO-Grenze aus dem ersten Bereinigungsschritt. Jedoch landet er nach diesem Abzug mit dem eigenen Wert von über einer Minute bei unter fünf Minuten in er Totalzeit und könnte demnach ein Kandidat zum Herauscleanen sein.
Welche Herausforderungen gilt es zu beachten?
Es existiert eine Vielzahl an Möglichkeiten, um mit Zeitverlaufsdaten zu arbeiten und auf Basis dessen ein Regelsystem aufzusetzen, dass ein besseres Quality Flagging als nur die Betrachtung der reinen Totalzeit ermöglicht. Selbstverständlich haben auch die vorgenannten Ansätze ihre Tücken und Grenzen, die es zu berücksichtigen gilt.
Es gibt diverse Gründe, weswegen ein Befragter bei der ein oder anderen Frage besonders viel Zeit benötigt hat. Dies kann zum Beispiel daran liegen, dass die Person lange zum Nachdenken brauchte oder einfach nur abgelenkt war. Daher ist es immer ratsam, die Zeitreihen im Kontext zu betrachten, um die Datenqualität wirklich sichern zu können. Man kann nur sichern, was man auch versteht.
Des Weiteren gehen die meisten präsentierten Ansätze von den Grenzwertbetrachtungen aus. Jedoch kann folgender Umstand hier eine Problematik für die Interpretation bereitstellen: Es kann nämlich auch sein, dass die Verantwortlichen für die Datenerhebung schlichtweg einen guten Job gemacht haben und die Befragten allesamt vernünftige Teilnehmer gewesen sind. Auch in solch einem Fall würden wir überschrittene Grenzwerte und Ausreißer sehen, die wir hier nicht übersensibel interpretieren dürfen, da diese in der Regel in Relation zur Verteilung der Daten ermittelt werden. Verständnis über die Daten ist hier der Dreh- und Angelpunkt.
Die Wichtigkeit von Datenqualität kann nicht oft genug betont werden. Nur zu oft sehen wir Studien, in denen de facto die Rohdaten gesammelt und ohne große Umschweife weiterverarbeitet werden. Es ist an uns Forschenden den Weg für Projekte zu ebnen, die wirklichen Mehrwert stiften.
Vielleicht können wir auch Ihnen helfen mehr aus dem Potenzial Ihrer Daten zu machen. Rufen Sie uns gerne einfach jederzeit an oder schicken Sie eine Mail an unsere Ansprechpartner für alle Fragen rund um Studiendesigns und Data Science. Wir sind für Sie da.