
Individualisierte Anzeige von Signifikanzen in GESStabs
Signifikanztests sind ein wichtiges statistisches Maß und äußerst beliebtes methodisches Verfahren in der Markt- und Sozialforschung: Über die untersuchte Stichprobe hinaus geben sie Auskunft darüber, ob sich die gesammelten Informationen auch auf die (entsprechende) Grundgesamtheit übertragen lassen.
Grundsätzlich besteht ein Signifikanztest in der Überprüfung einer theoretisch begründeten Hypothese über den systematischen Zusammenhang zwischen zwei Variablen. Statistisch wird dies umgesetzt durch einen Vergleich der gemessenen Werte und der Stichproben-Verteilung mit einer Standardnormalverteilung.
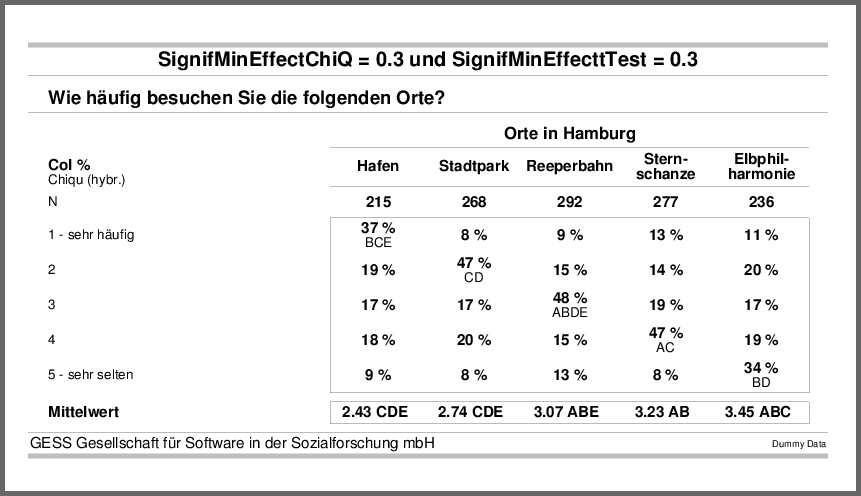
In GESStabs stehen eine ganze Reihe von Signifikanztests für gewichtete und ungewichtete Daten zur Verfügung. Signifikante, d.h. nicht zufällig entstandene, Unterschiede zwischen zwei Messwerten werden mithilfe von Buchstaben in den Datenzellen markiert. Häufig werden verschiedene Testverfahren kombiniert und nebeneinander in der Datentabelle ausgewiesen. Nun liegt es in der Natur der Sache, dass mit wachsender Stichprobengröße mehr und auch kleine(re) Differenzen signifikant sind, denn: Je mehr Teile einer Population erfasst werden, desto wahrscheinlicher ist es, dass die Stichprobe die tatsächlichen Merkmalsausprägungen der Grundgesamtheit abbildet. Auch wenn signifikante Ergebnisse erwünscht sind, ist eine Interpretation vieler signifikanter, aber kleiner Zusammenhänge meist nicht zielführend. Zudem macht die Markierung allzu vieler Tabellenzellen mit Signifikanzbuchstaben eine Tabelle voller und unübersichtlicher. Es ist also sinnvoll, die Ausweisung signifikanter Effekte in Tabellen auf die wesentlichen Stellen zu beschränken.
Zu diesem Zwecke wurde — auf Wunsch einer langjährigen Kundin — ein neues Feature entwickelt, das die folgende Funktion beinhaltet: Die Kennzeichnung von Signifikanz wird unterdrückt, wenn ein vorgefundener Unterschied zwischen zwei Messwerten einen vom Benutzer definierten Mindestwert nicht erreicht. Hierfür werden zwei Maße der Effektstärke genutzt, die sonst auch als Zusammenhangsmaße verwendet werden, nämlich Cramer´s Phi für Unterschiede zwischen Anteilswerten (Prozentwerten) und Cohen´s d für Mittelwerteunterschiede. Der Wertebereich von Cramer´s V liegt zwischen 0 (kein Effekt) bis 1 (absoluter Effekt), Cohen´s d kann auch Werte über 1 annehmen. Als Minimalausprägung, die eine Differenz annehmen muss, um als relevant signifikant markiert zu werden, wird eine Mindest-Effektstärke angegeben. Wird eine Signifikanz-Kennzeichnung unterdrückt, wird dies in der im Zuge der Signifikanzprüfung erstellten stats.txt-Datei vermerkt. Die entsprechenden neuen Funktionen heißen
SIGNIFMINEFFECTCHIQ
und
SIGNIFMINEFFECTTTEST
und werden syntaktisch so definiert:
SIGNIFMINEFFECTCHIQ = <Mindestwert>;
bzw.
SIGNIFMINEFFECTTTEST = <Mindestwert>;
Das unten stehende Beispiel veranschaulicht die Auswirkung der neuen Funktion.
Zunächst sehen Sie hier eine Tabelle mit Dummydaten, in der alle Signifikanzen ausgewiesen werden.

Anschließend sollen nur signifikante Effekte ab einer Stärke von 0.3 markiert werden.
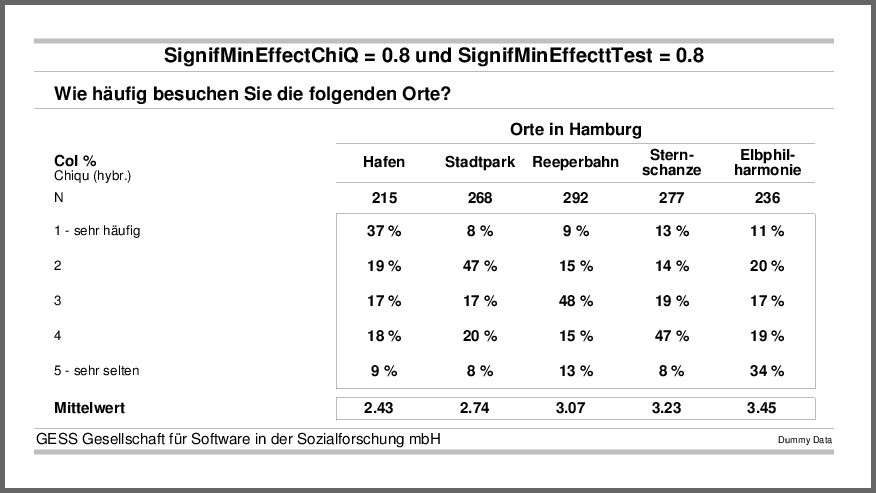
Wird die Ausgabe der Signifikanzbuchstaben auf einen Minimaleffekt von 0.7 beschränkt, werden nur noch hohe signifikante Mittelwertedifferenzen angezeigt.

Eine signifikante Effektstärke von über 0.8 weist schließlich keiner der in der Tabelle dargestellten Differenzen mehr auf — davon ist auch bei fiktiven Daten in der Marktforschung nur zu träumen.
Die beschriebene neue Funktion ist ein Beispiel dafür, wie Anforderungen aus der Praxis unsere Software formen, ihre Leistungsfähigkeit erhöhen und damit Ihre Arbeit immer weiter erleichtern — aus der Praxis, für die Praxis!
Übrigens: Hier informieren wir Sie stets über neue Funktionen und Einstellungen unserer Softwareprodukte.